log
assets
第二节讲义_1682136737988_0
{kind=link}
{kind=link}
_-_image_1705670873910_0.png){kind=link}
_-_image_1705670919100_0.png){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
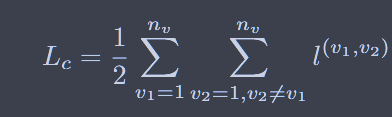{kind=link}
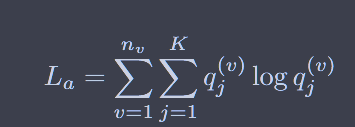{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
journals
loom
pages
static
css
{kind=link}
fonts
inter
icons
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
img
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
js
excalidraw-assets
locales
pdfjs
cmaps
tags
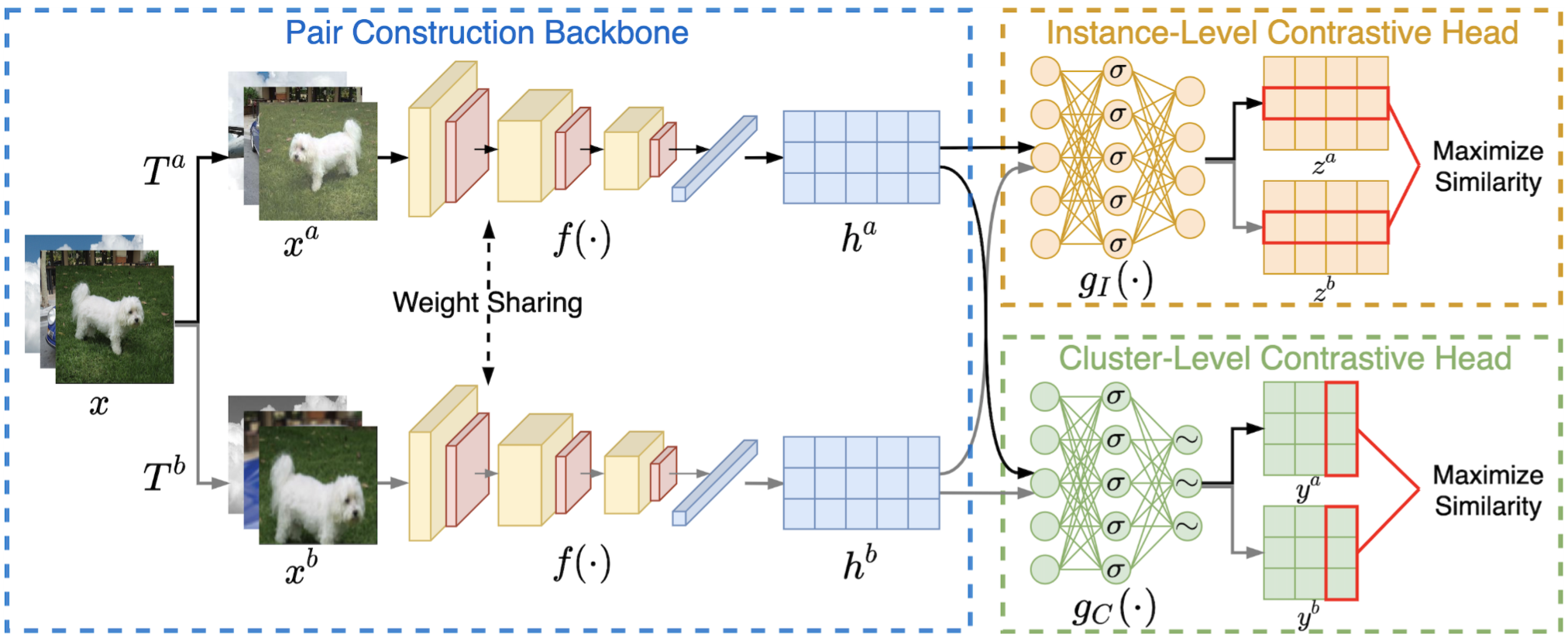
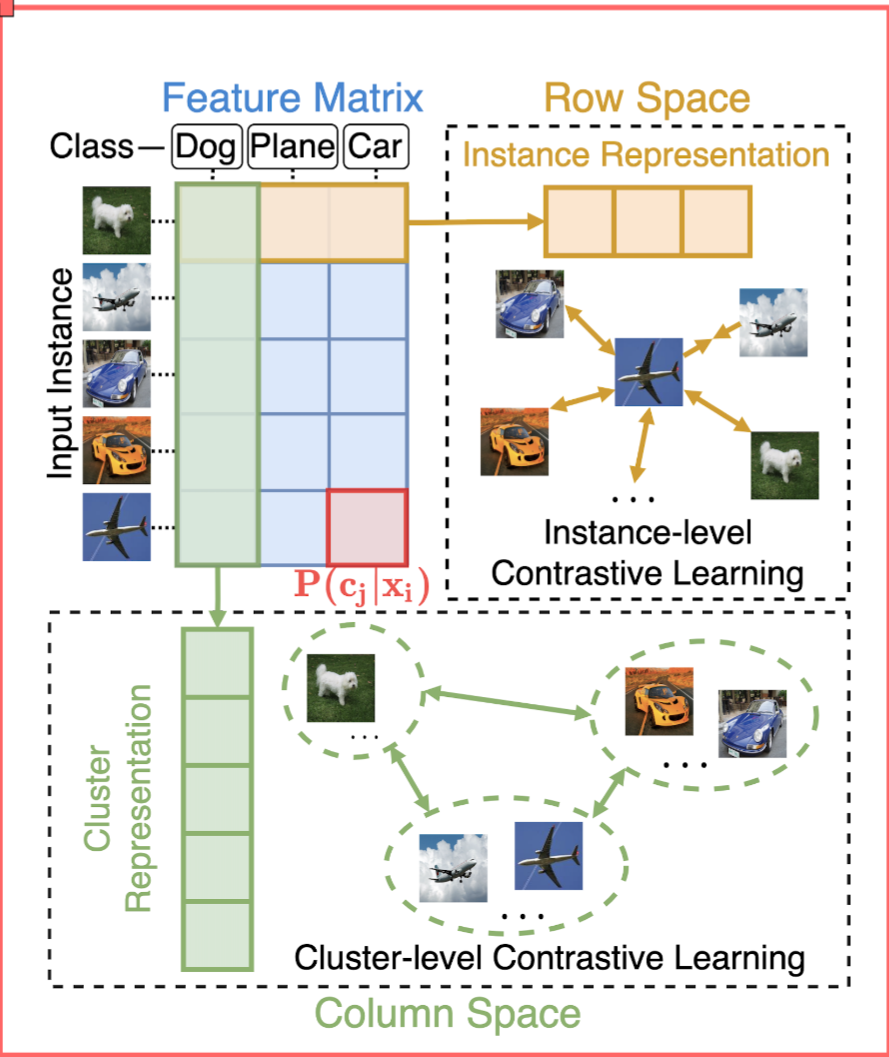
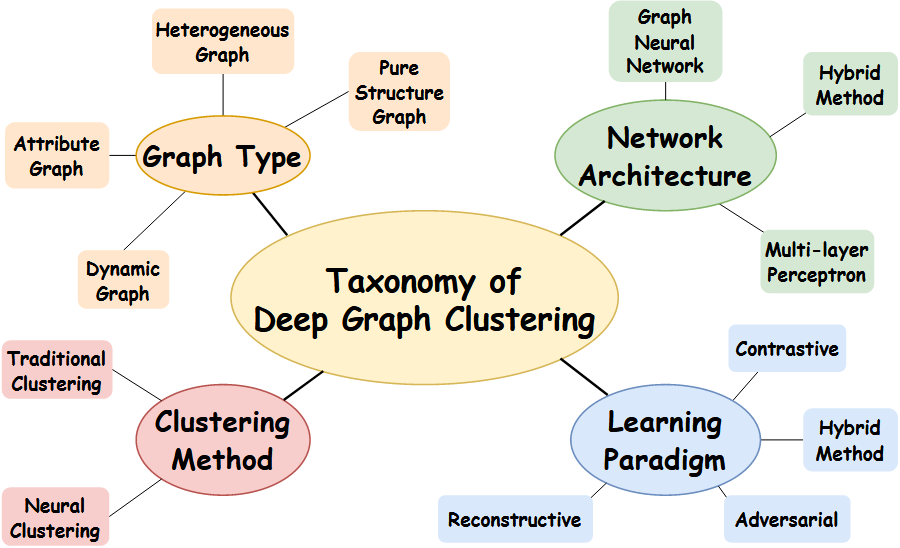
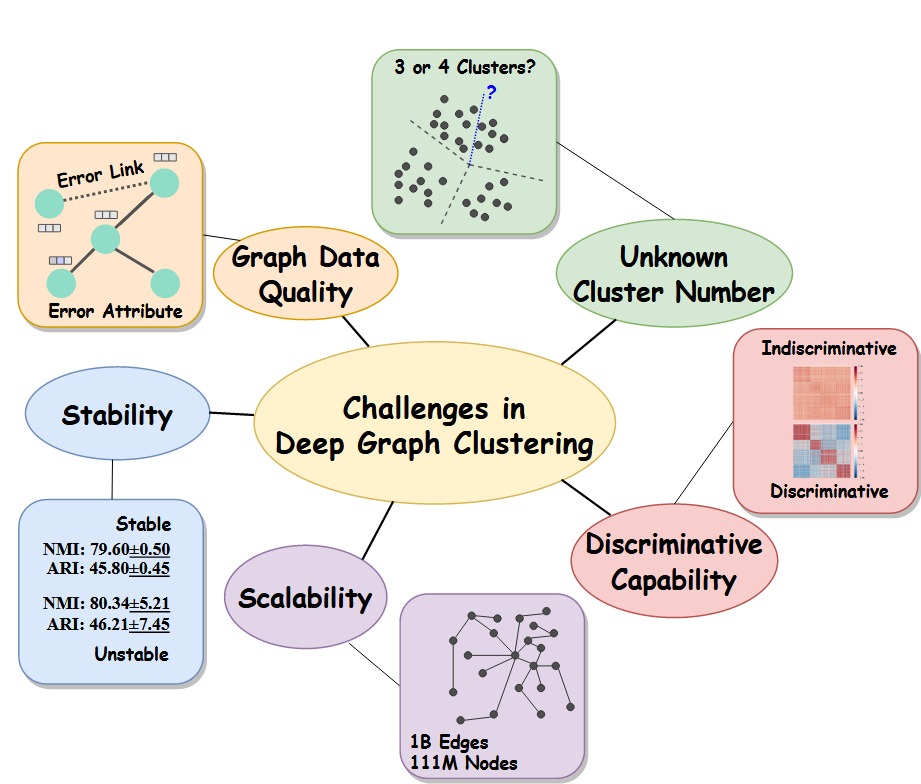
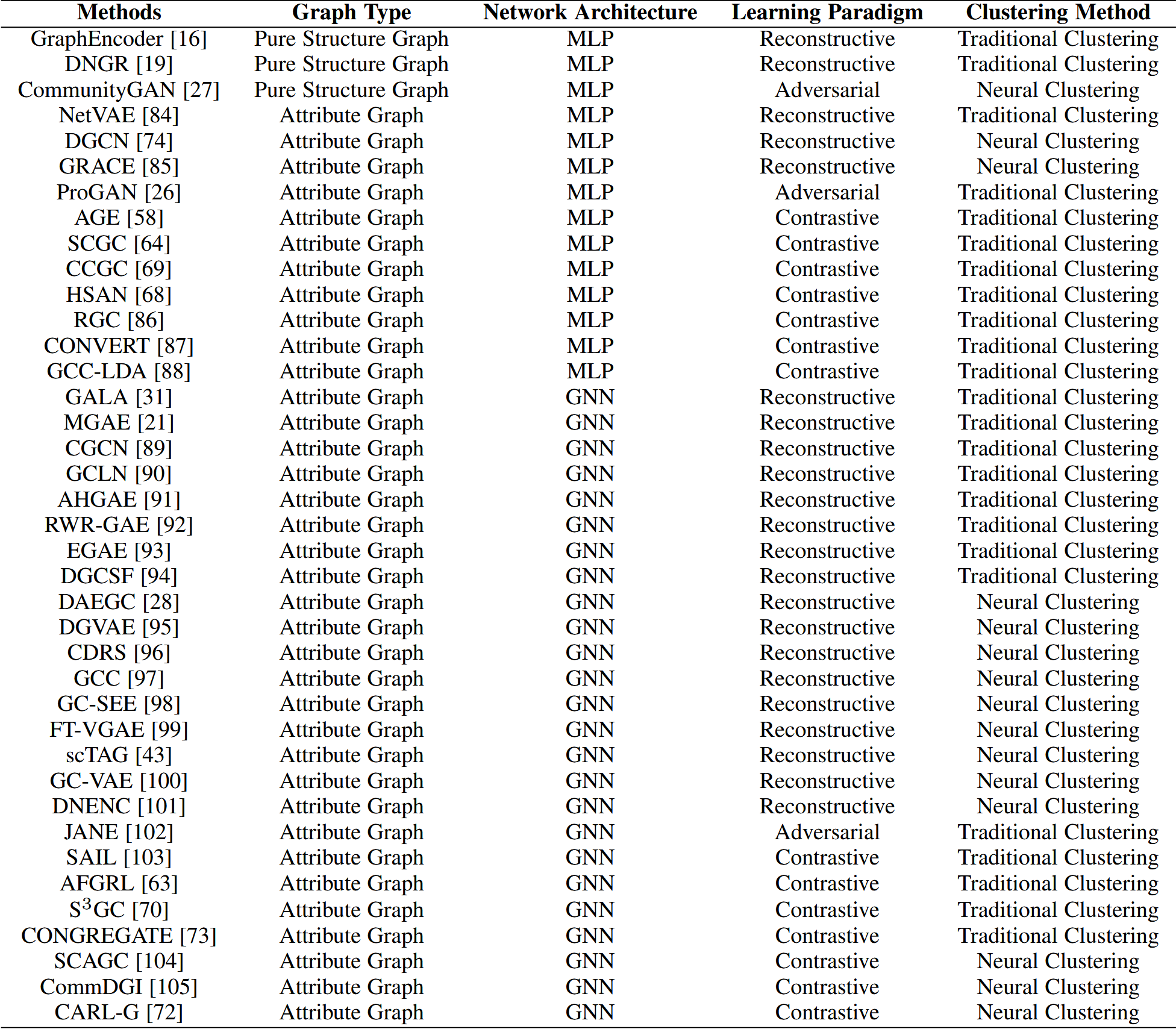
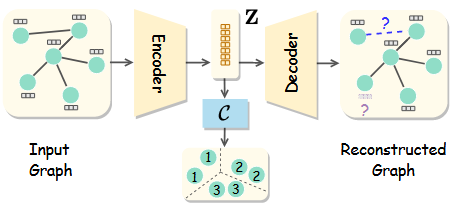
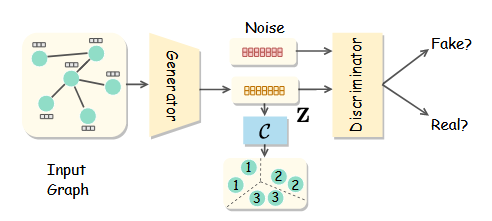
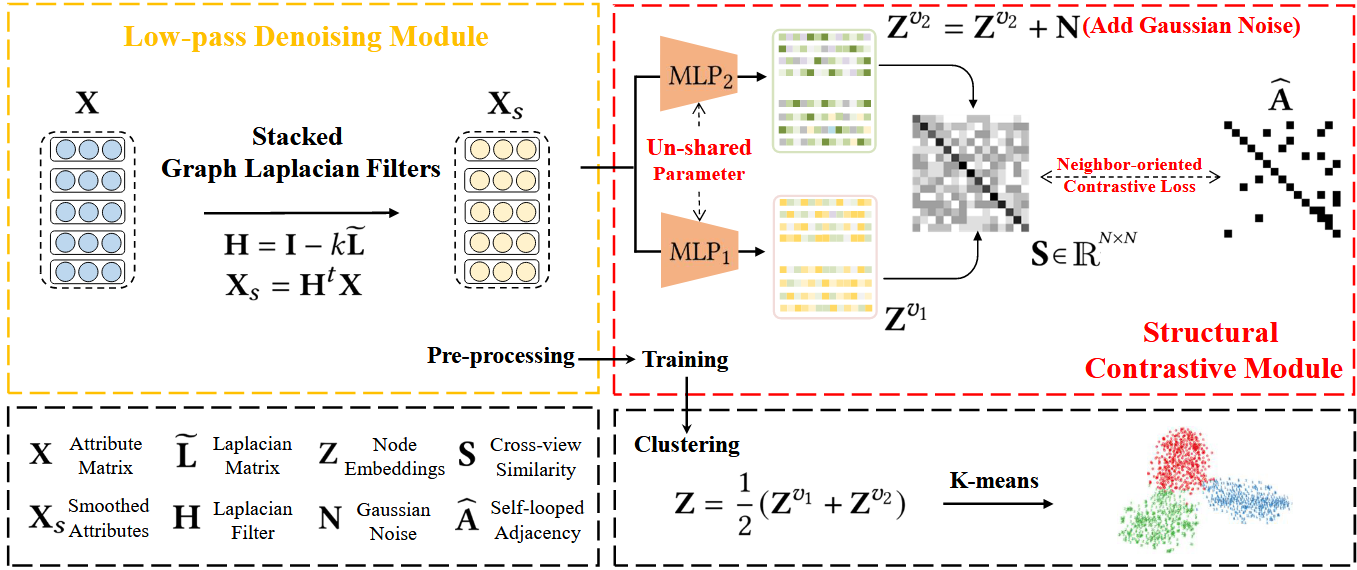
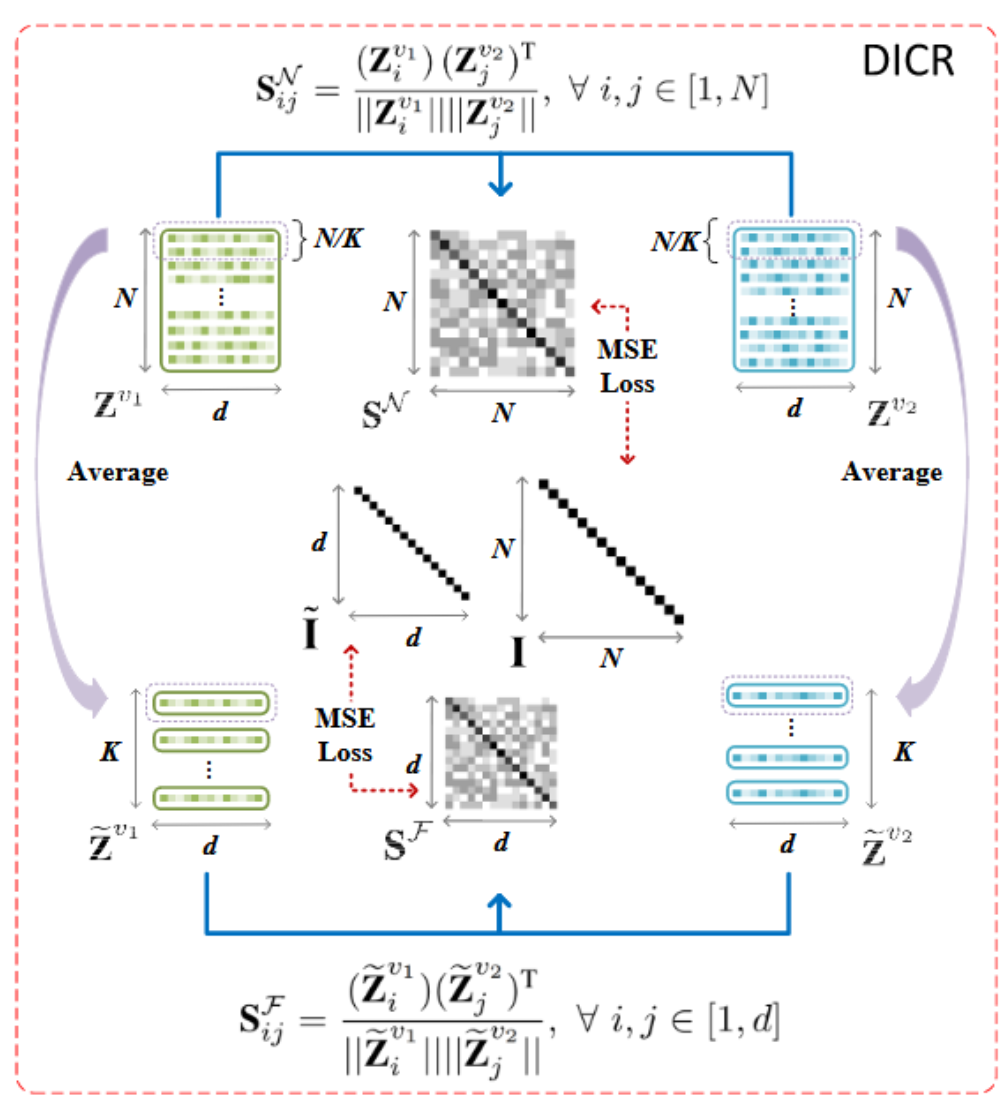
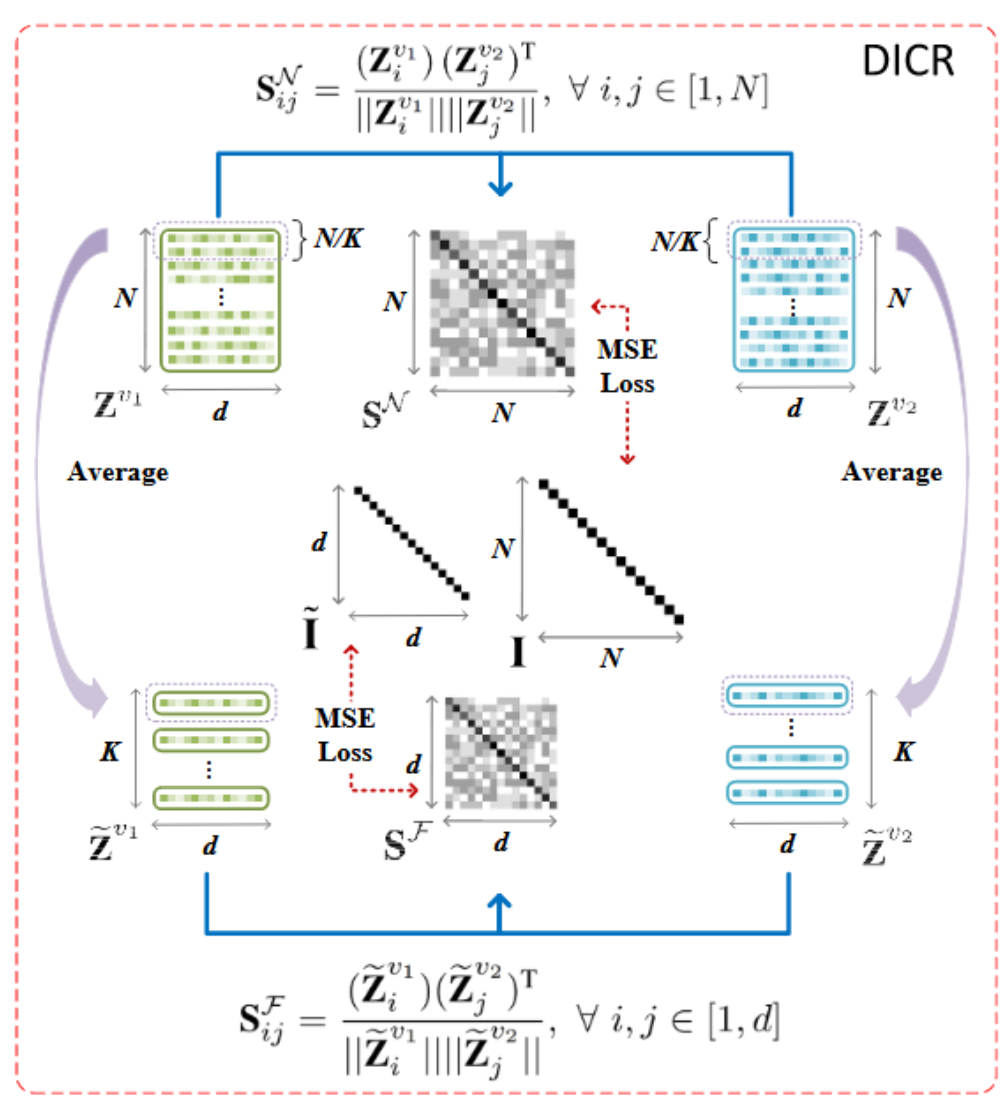
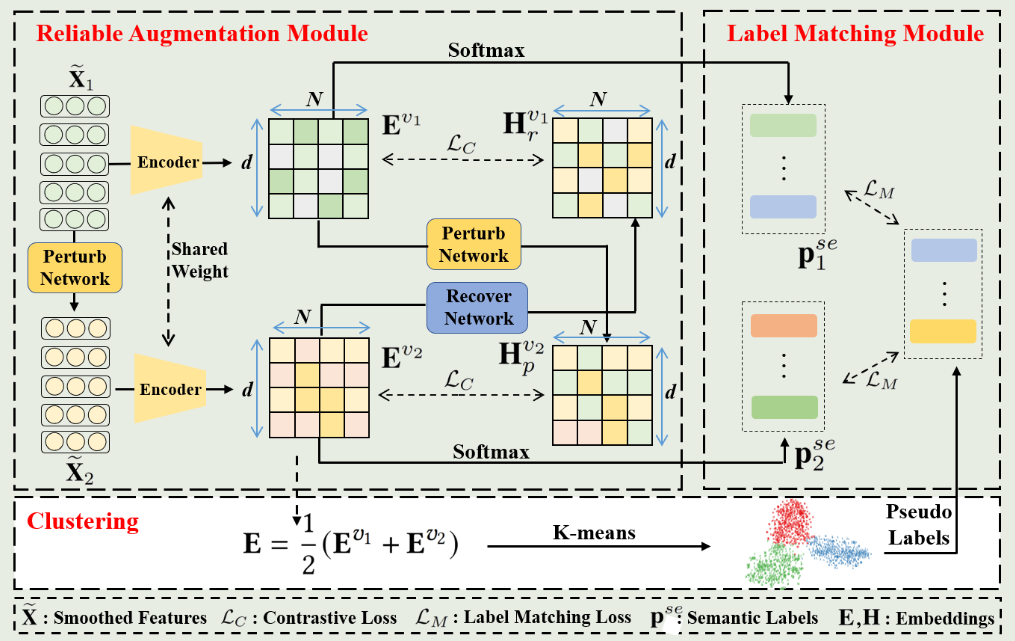
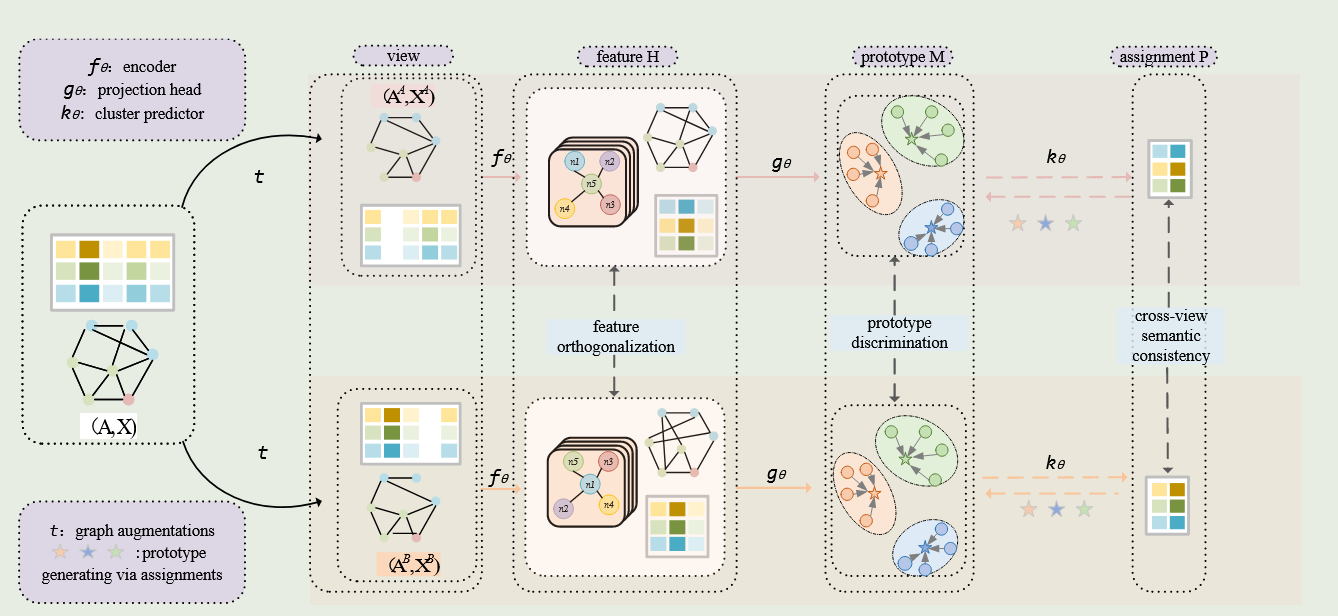
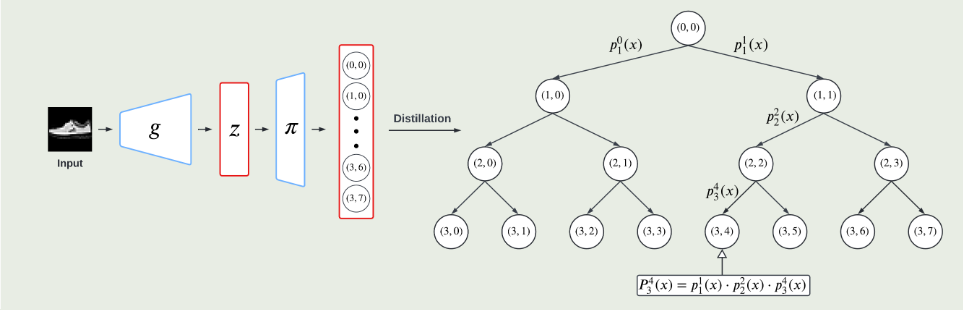
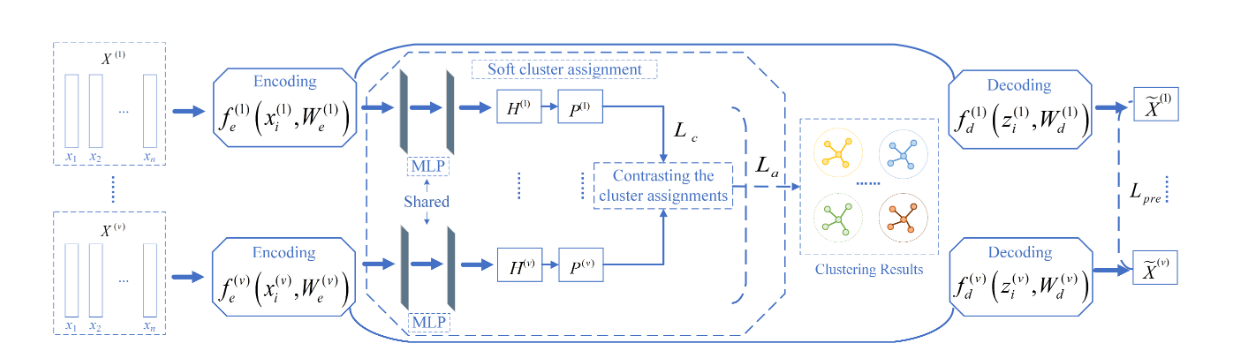
3月实验进展
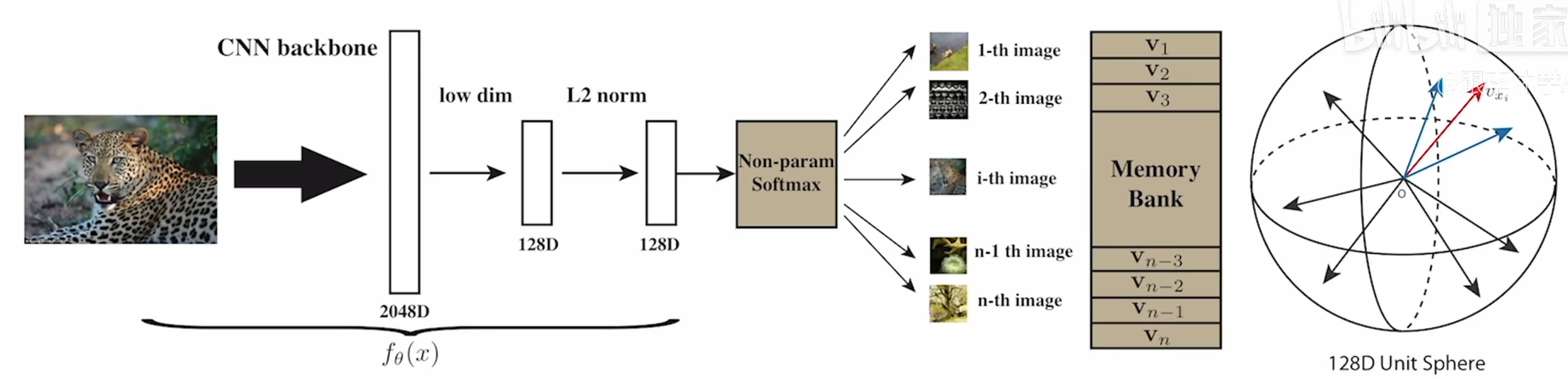
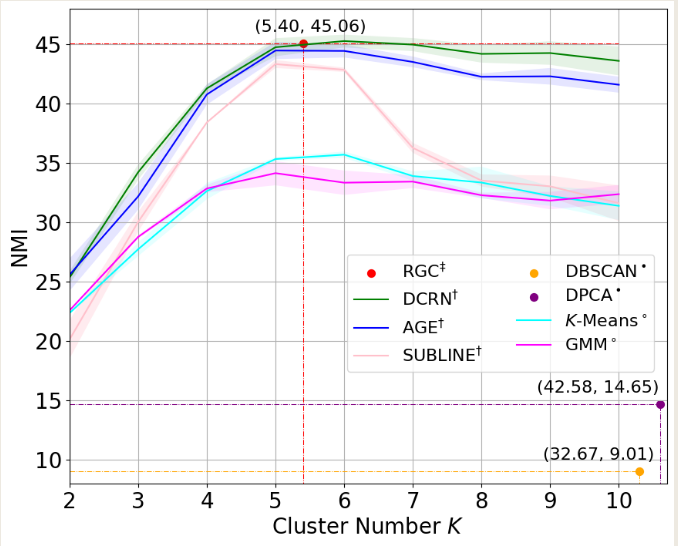
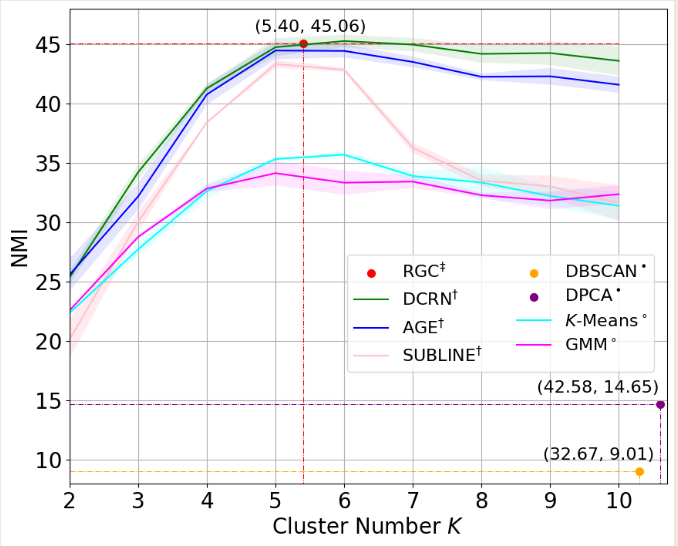
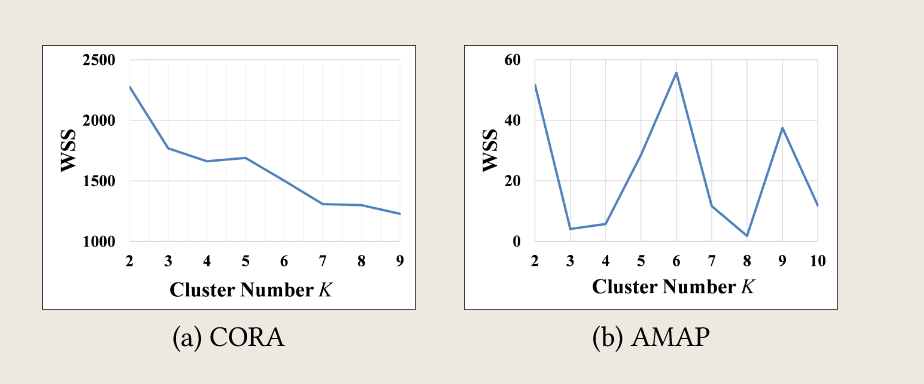
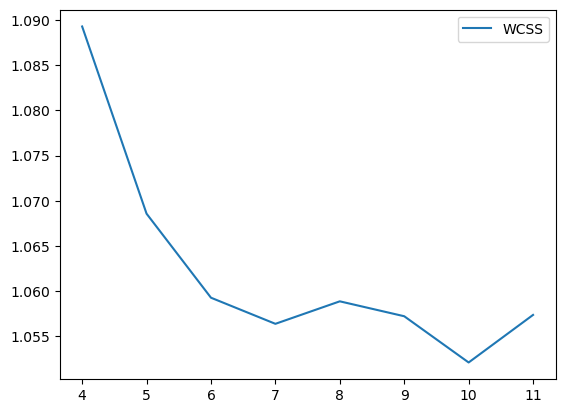
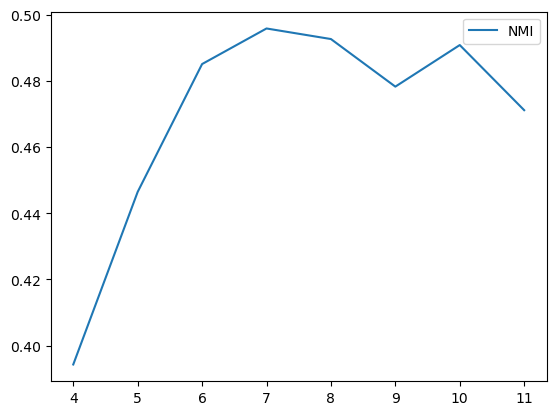
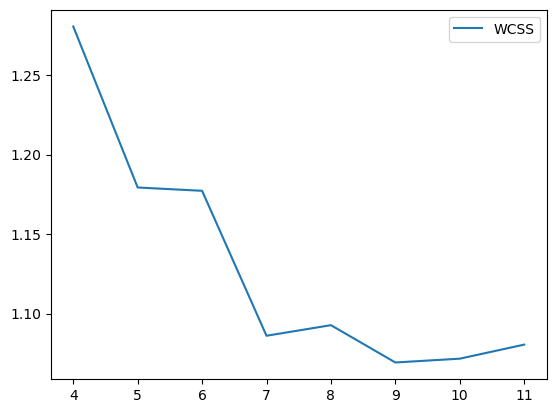
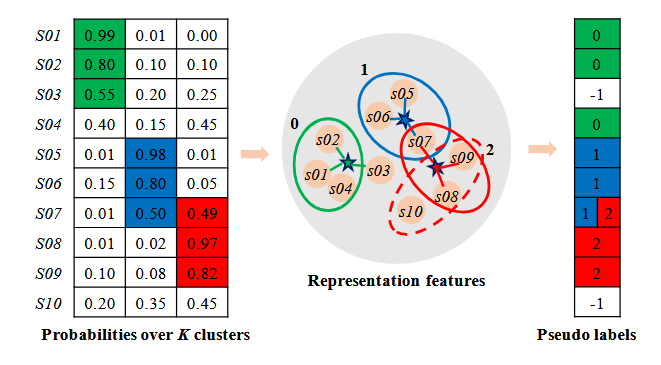
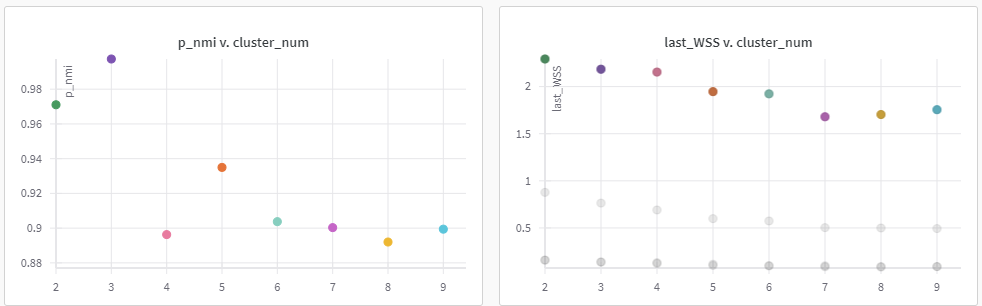
cora数据集,cluster num=7,如图,可能取值为7或者10
实验原因:
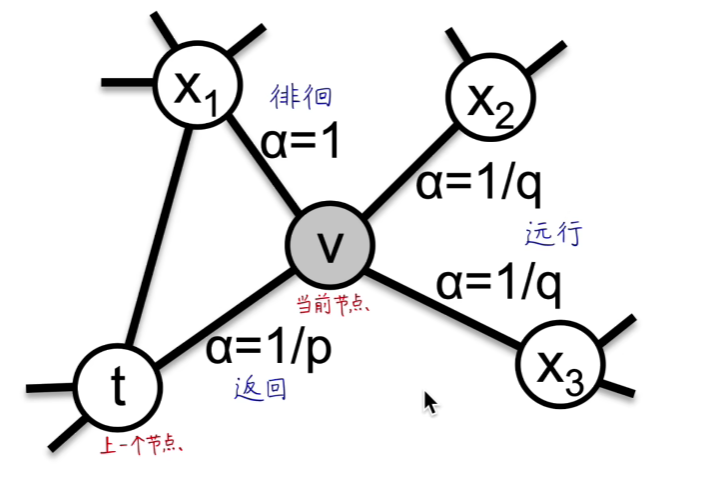
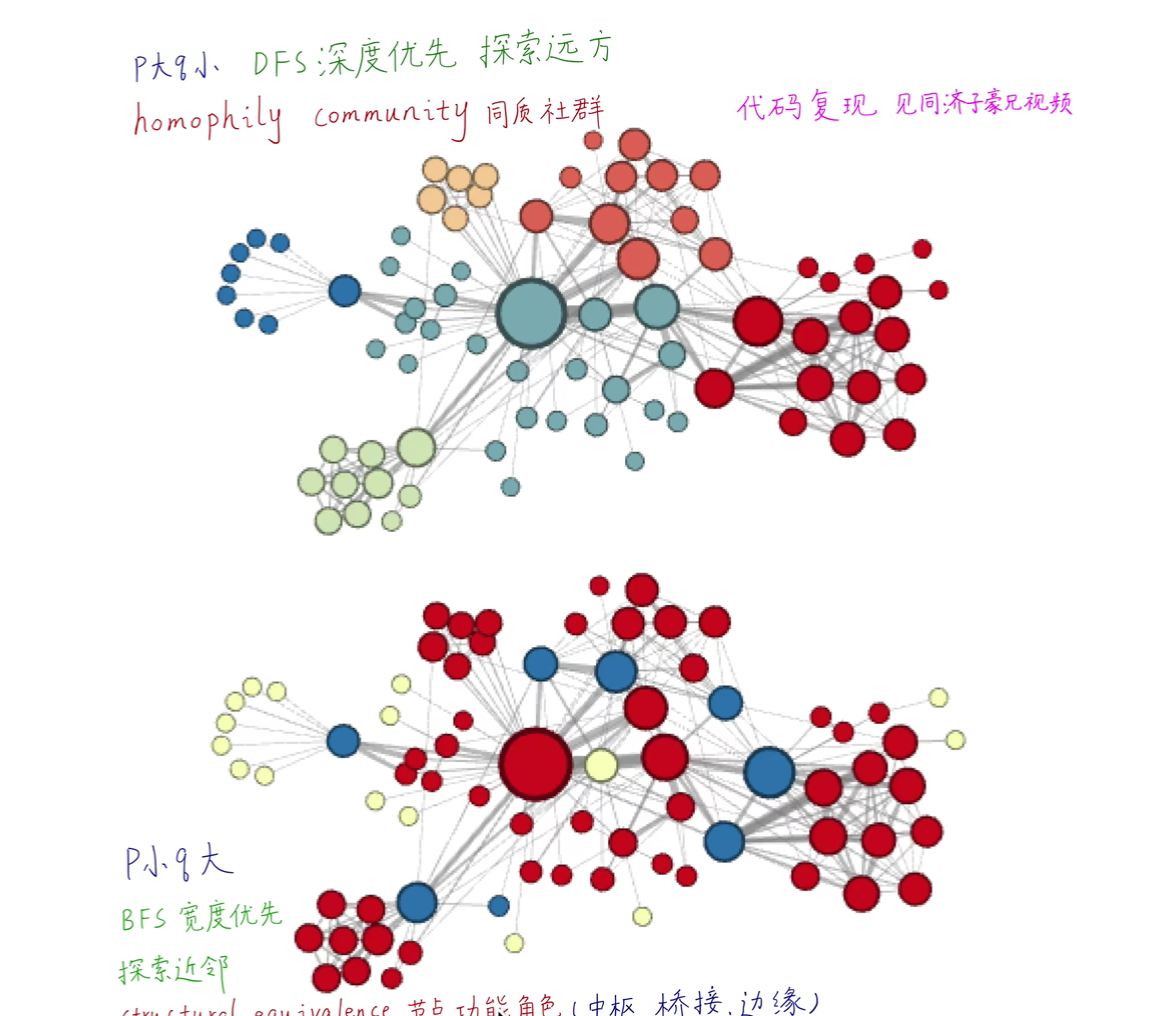
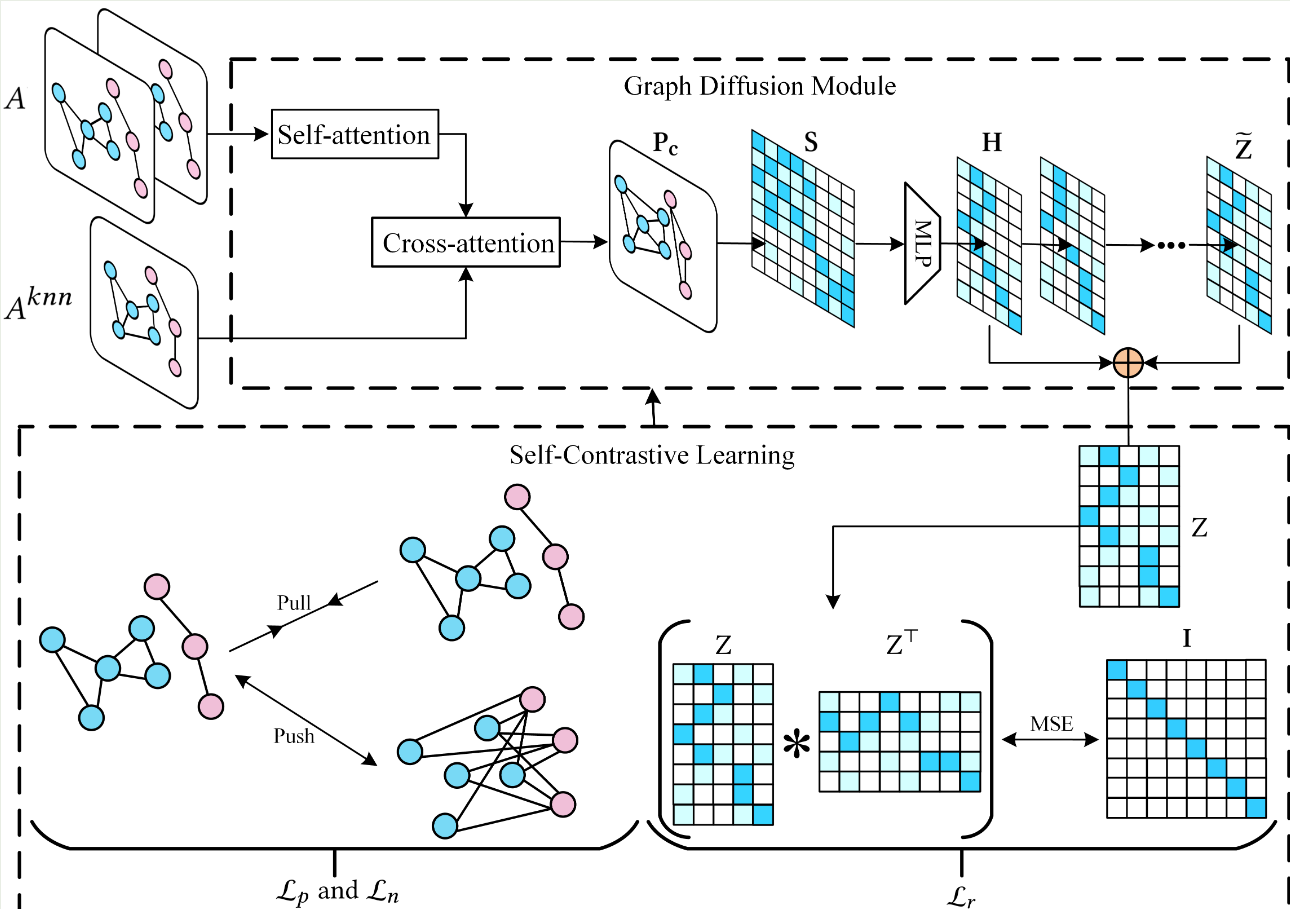
去年十月那个人写的本质上是ELBOW,即kmeans自适应聚类数的改进,而中心聚类并没有被做.因此我现在在做中心聚类
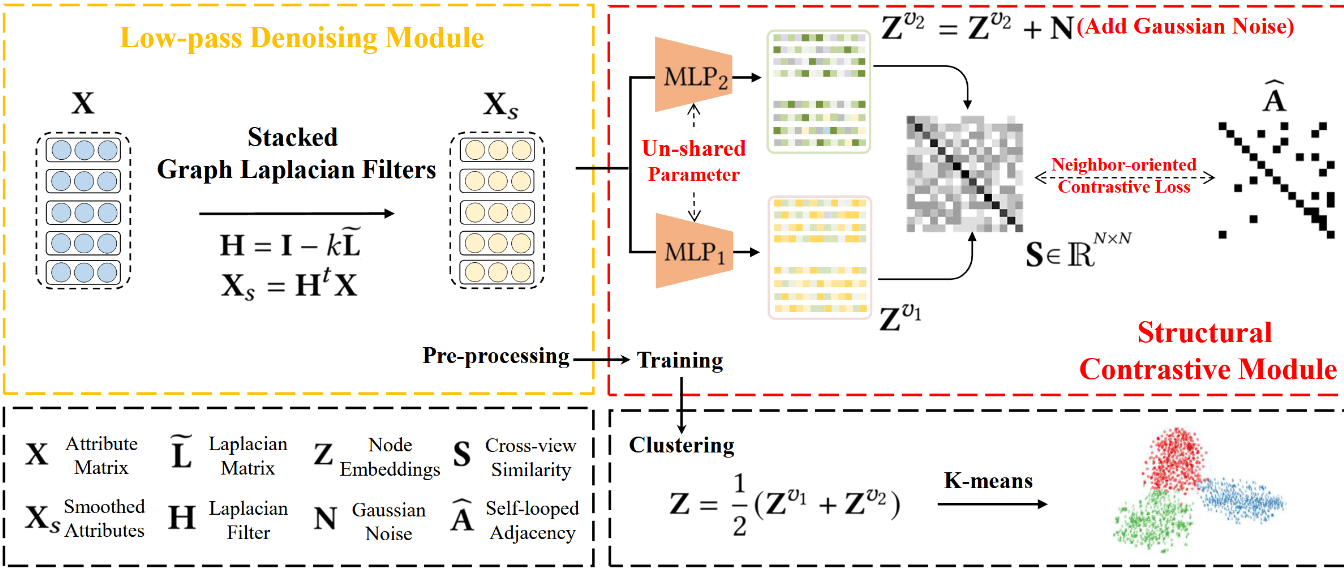
优势:理论上可以用于大图
实验结论:有待更进一步实验
实验设置:
由于刚写完实验,实验仅仅在cora数据集上测试,seed=8,并且此方法并未进行复杂图/数据增强,因此NMI现在只有50%(其他人实验,用了增强,理论上可以到60左右,即第二的水平)
简言之,相当于未优化的kmeans
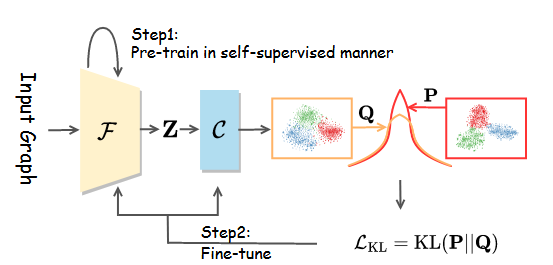
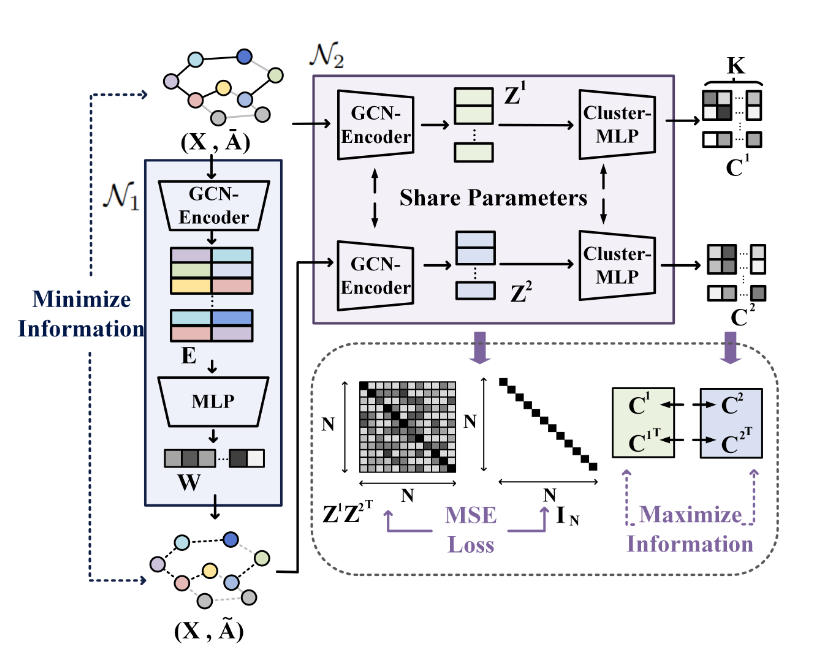
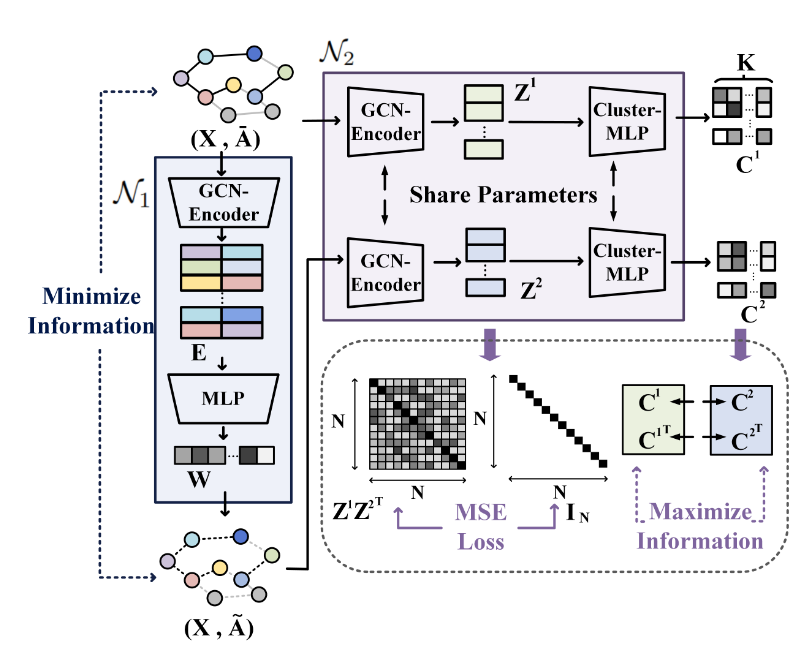
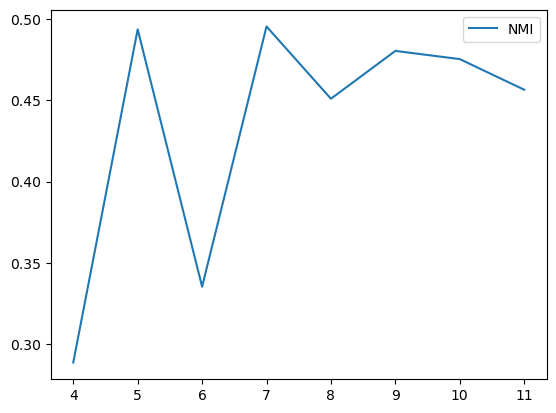
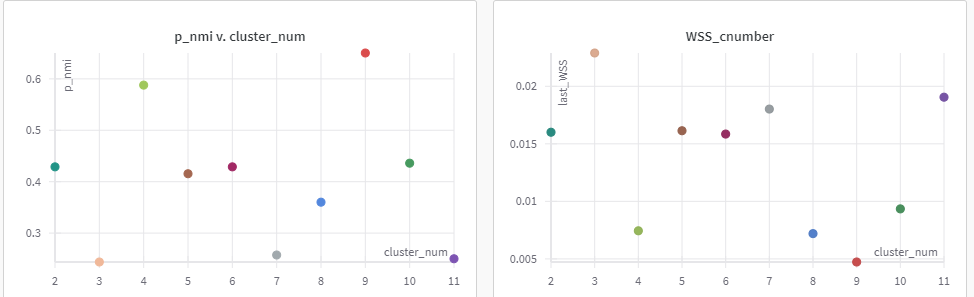
方案一:对比聚类损失正则化,在为其分类(聚类)的时候不正则化


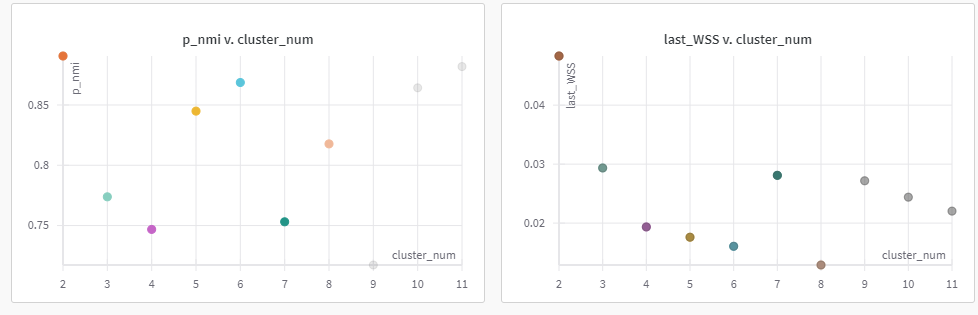
方案二:两个都不正则化:


总结:显然,方案一的效果好
猜测原因:常规对比学习前会先进行正则化,来规整向量.这个同理
两个方案均在NMI高的位置,取得可能得聚类数